How to publish large events with Amazon EventBridge using the claim check pattern.
Example of how to raise events with large payloads using Amazon EventBridge.
David Boyne
· 8 min read
In the previous blog post we explored how you can enrich your EventBridge events using Lambda, and now let's explore how we can deal with large payloads with Amazon EventBridge.
Amazon EventBridge is a serverless event bus that provides ways to create decoupled event-driven applications. We can define custom events and use EventBridge to create rules, targets, filters for our consumers.
When building event-driven applications it’s important for us to consider the producer/consumer event contract and design our events in ways that can help scale our architecture.
Like many brokers, EventBridge has a limit on the payload size of the events you can produce. Most of the time your events may be well under this limit and you are fine, however other times you may want to add larges amounts of information into your events that push you over the 256kb limit.
So how can we design and raise events in our event-driven architectures that bypass payload limits?
This is where the claim check pattern can help.
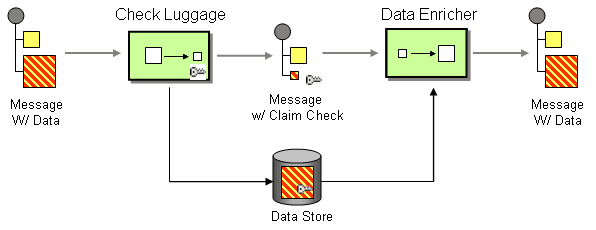
Claim check pattern from https://www.enterpriseintegrationpatterns.com/StoreInLibrary.html
The claim check pattern allows us to store information first, then raise the event with a path back to the information for downstream consumers.
In this blog post we will explore an event-driven pattern that uses claim check pattern to help us raise large events with EventBridge and give consumers a way to receive the information (using pre-signed URLs). We will be using EventBridge notifications from S3 and transform these events into business Domain events and give downstream consumers a pre-signed URL back to the data in S3.
Grab a drink, and let’s get started.
•••Why use the claim check pattern?
When building event-driven applications it’s important you think about the contracts between producers and consumers. Many people use EventStorming or Event Modeling to help them identify and design events.
Event storming example, highlighing events, domains and actors.
You may identify or design events that have a payload larger than the allowed limits of your broker. With Amazon EventBridge this limit is 256kb.
Depending on your event design and the information you want to send, will determine if you exceed the payload size limit. If you want to send large amounts of information inside your events you will need to use a pattern like the claim check pattern.
With the claim check pattern, you can store information first (S3 in this example) and then give consumers ways to get this information downstream (identifier back to resource).
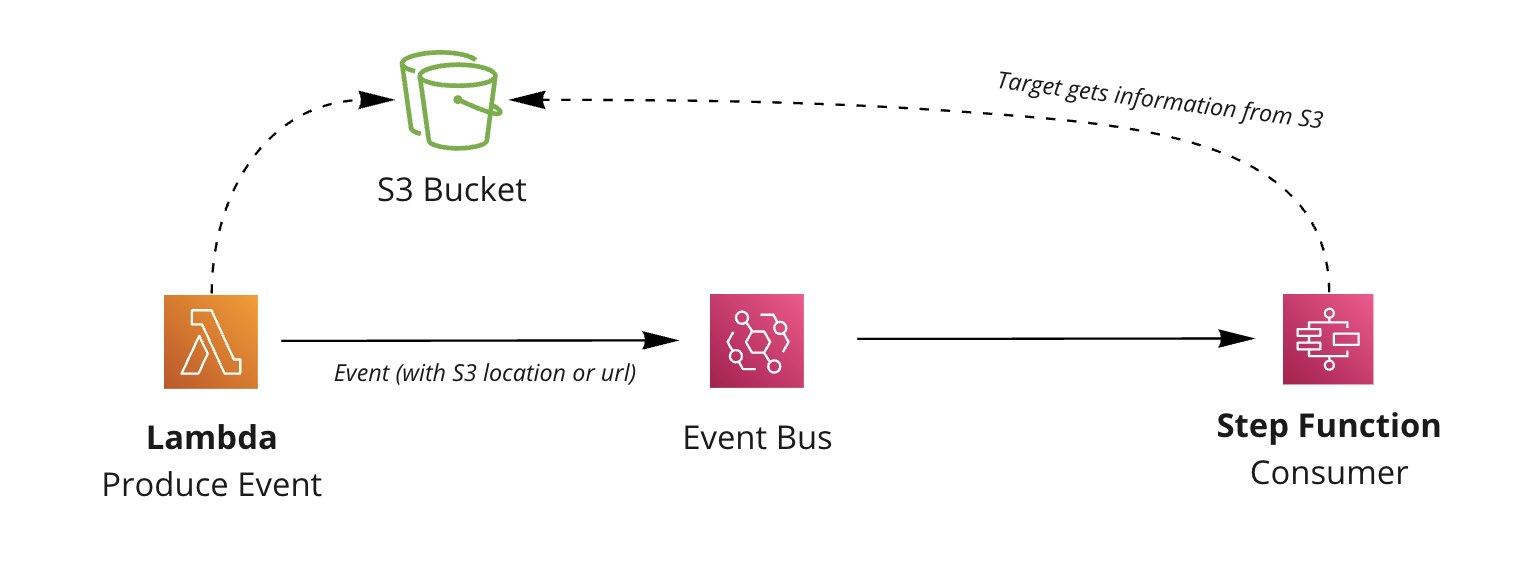
Example of producer storing data first, then consumer reading the location of the data.
For consumers to get the information stored from the producer you have options:
- Give consumers permissions to read the location of the data (IAM permissions for database or S3 for example)
- Give consumers a pre-signed URL for the data so they don’t need explicit permissions.
Both have trade-offs, but for this example we will be exploring the pre-signed URL solution.
Using S3 notification events we can actually automate the check claim pattern. The pattern in the next section will explore a use case where users upload a file to S3, we use EventBridge notifications to process the events into custom Domain Events and downstream consumers can read the information required using a pre-signed URL.
Let’s dive into the example.
•••Using S3 notifications with EventBridge to process large events.
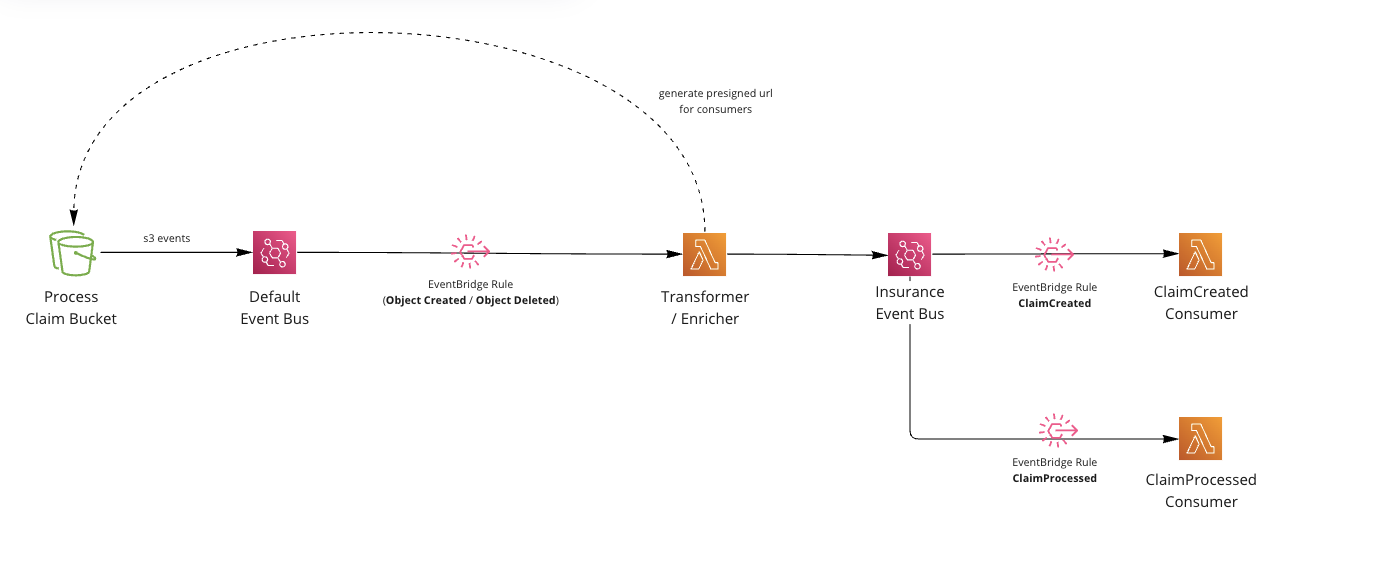
Let’s assume we are running an insurance company. When our customers want to make a claim, a file is upload into the bucket, this generates a ClaimCreated event. In the future when the claim has been processed, the file is removed from the bucket creating the ClaimProcessed event.
We listen to AWS S3 events and transform them into Domain events. These events having “meaning” to our (pretend) company, and have been designed by the team.
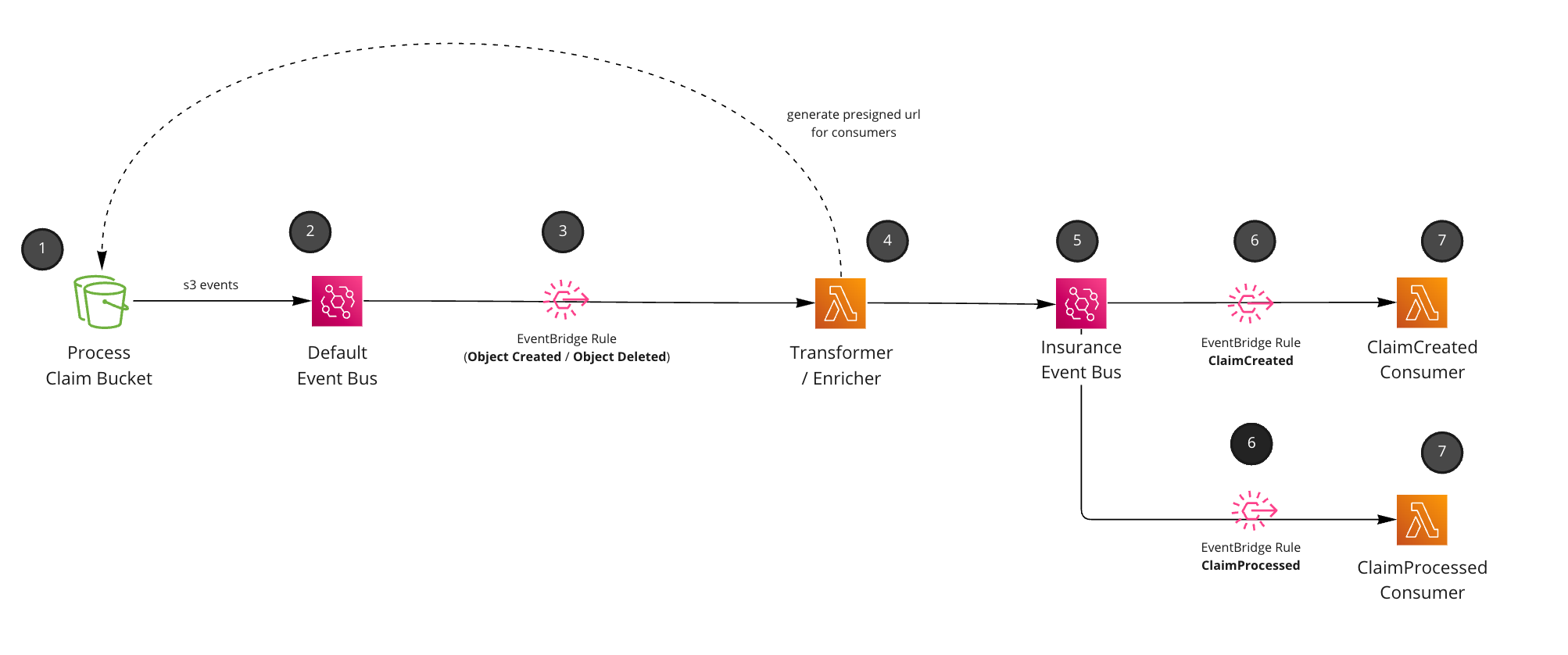
Pattern using S3 EventBridge notifications, pre-signed URLS and consumers.
-
User uploads information into a bucket. We just assume here this could be from an external API or upload directly into the bucket. In this example we assume that an
insurance claimhas been inserted into the bucket for processing (pretend business requirement). -
We configure our S3 bucket to send events to EventBridge. These events are sent to your
defaultevent bus. Every AWS account has one.
// Create a new S3 bucket for claim processing (cdk)
const bucket = new s3.Bucket(this, 'claims-bucket', {
removalPolicy: RemovalPolicy.DESTROY,
// All s3 events will go to eventbridge here (default bus)
eventBridgeEnabled: true,
})
- Setup an EventBridge rule to only listen for files inserted into the claims folder and S3 objects that have been Created (Object Created event) or Deleted (Object Deleted event). Note: This is just an assumption of how we want to use our S3 bucket, you can listen to anything here. This “business requirement” was to use S3 as a processing bucket, we assume any files removed from this bucket indicates that the claim has been processed.
{
// source will S3
source: ['aws.s3'],
// only listen to Object Created and Object Deleted (many more available)
detailType: ['Object Created', 'Object Deleted'],
detail: {
object: {
// custom prefix, we want to process the claims folder in bucket
// when user uploads file it will be /claims/{user-id}/{file}.
key: [{ prefix: 'claims/' }],
},
},
}
- Lambda picks up the raw S3 events. We transform these events into
Domain events(events that actually make sense in our domain, ClaimCreated and ClaimProcessed). Events are enriched with data, and we create a pre-signed URL to our S3 document which expires after an hour (for downstream consumers).
export async function handler(event: any) {
// transform S3 event into domain event with presigned url
// code can be found on https://github.com/aws-samples/serverless-patterns/blob/main/s3-to-eventbridge-claim-check-pattern/cdk/src/s3-to-domain-event-transformer/index.ts
const transformedEvent = await transformS3Event(event)
// send domain event into custom bus
await client.send(
new PutEventsCommand({
Entries: [transformedEvent],
})
)
}
-
Events are published into a custom event bus.
-
Rules are setup for downstream consumers of our Domain Events (ClaimCreated, ClaimProcessed).
// Rule and pattern for ClaimCreated
{
detailType: ['ClaimCreated'],
}
// Rule and pattern for ClaimProcessed
{
detailType: ['ClaimProcessed']
}
- Consumers receive the Domain Events and process as they see fit. (This example just logs out, but you could email, send to other targets etc).
That’s it. We have a pattern the listens to S3 events and creates custom Domain events with pre-signed URLs. Consumers can use the URLs downstream to get the information from S3.
Things to consider with this pattern
This pattern is mainly a proof of concept, and hopefully shares with you a way to expand EventBridge event size limits using the claim check pattern. This pattern assumes some “business requirements” and focused on processing insurance claims, but the underlying pattern and integration could be used for anything.
- This pattern uses a pre-signed URL valid for an hour, you may want longer, or want to manage permissions with IAM (without the need for pre-signed URLS). Then all downstream consumers that want this information would need permissions to read the file.
- Listening to S3 events has a cost
$1.00/million custom events from opt-in AWS services (e.g., Amazon S3 Event Notifications), read more about pricing here.
Summary
It’s important with any event-driven application to consider the contracts between producers and consumers and what patterns are available to help us maintain this relationship.
You might run into cases where your event payload exceeds the 256kb limit of EventBridge, and need to store the data first, and give downstream consumers ways to get the information required, we can do this using the claim check pattern.
Amazon S3 is a great place for us to store information for our events, and we can even use S3 EventBridge notifications to trigger an automatic claim check pattern for downstream services.
In this blog post we explored using S3 events and transforming them into domain events with pre-signed URLS for downstream consumers to get information they need. This is all event-driven and triggered when new files are created or deleted from our bucket.
If you are interested in using S3 as a storage solution for your event data, you can read the code here and explore the pattern more on serverlessland.com.
I would love to hear your thoughts on the pattern or if you have any other ideas for similar patterns, you can reach me on Twitter.
If you are interested in EventBridge patterns I have more coming out soon, and will be covering patterns like:
- Enrichment with AWS Lambda (out now)
- Outbox pattern with EventBridge
- Enrichment with Step Functions
- Enrichment with multiple event buses
- And more….
Extra Resources
- Enterprise integration patterns: Claim check pattern (website)
- S3 EventBridge Claim Check pattern: Serverless Land (code/website)
- Code for pattern shown on blog post (code)
- Serverless EventBridge patterns (80+)
- Talk I done around Best practices to design your events in event-driven applications (video)
- Over 40 resources on EventBridge (GitHub)
Until next time.

David Boyne
Maintainer EventCatalog | Advocate | Consultant | Enjoy learning things and sharing as I go.